NeuroTrace
A framework for analyzing how AI behavior changes over time
NeuroTrace is an analytics framework that turns AI conversation logs into structured behavioral data. It helps researchers and engineers examine how an assistant’s patterns change across repeated interactions, moving personalization analysis beyond intuition and into something measurable.
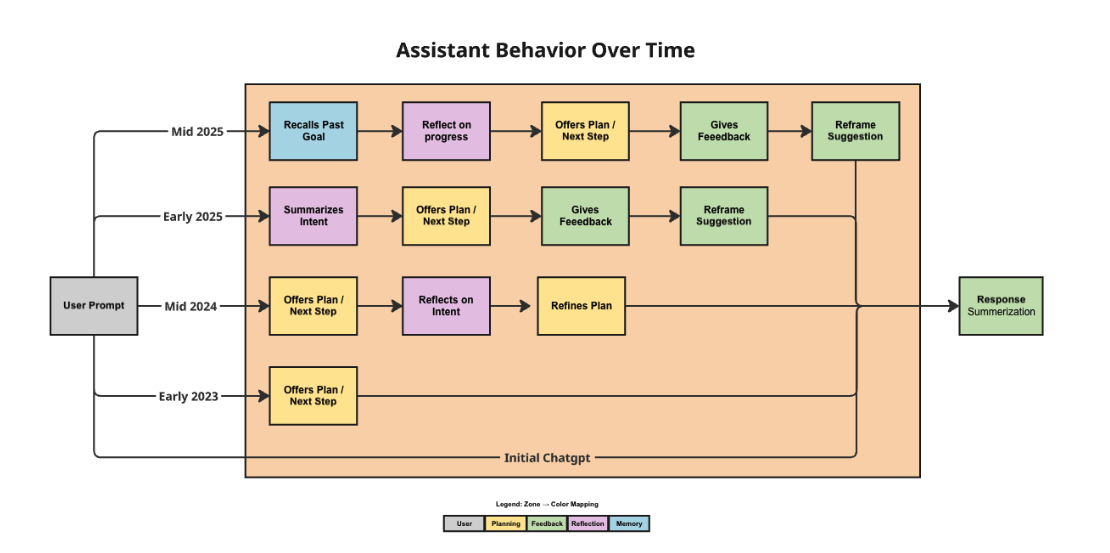
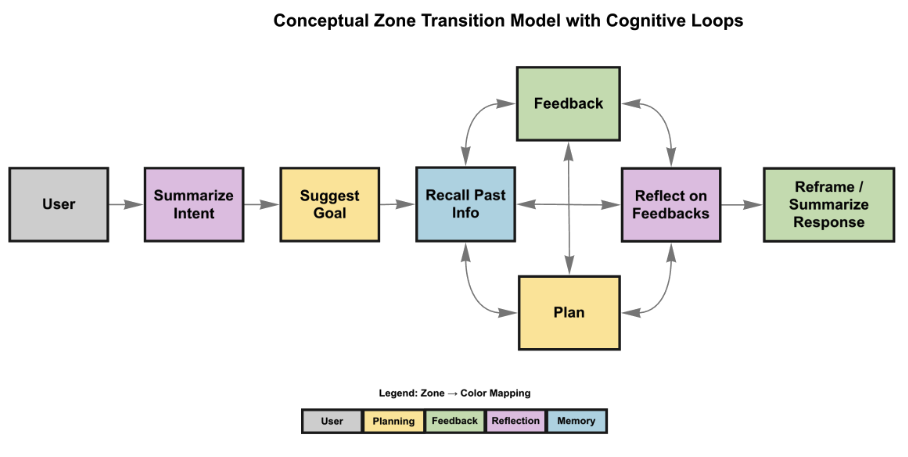
Example: Mapping a corrective loop
NeuroTrace does more than show whether a response was good or bad. It can reveal patterns in how the assistant changes its behavior after user feedback, such as a recurring shift from feedback events into planning-oriented responses. This makes it possible to study whether the system is adapting in useful ways over time rather than just sounding more personalized.
The Problem: Personalization is hard to inspect
Memory-enabled AI systems adapt to users over time, but that adaptation is usually hard to observe in a structured way. Most evaluations look at isolated outputs or general user satisfaction, which makes it difficult to understand how behavior actually shifts across many conversations or whether those shifts improve usefulness, alignment, or safety.
The Outcome: Measurable behavioral analysis
NeuroTrace provides a repeatable way to analyze behavioral change in AI systems by transforming raw logs into structured outputs and interaction graphs. This gives three practical outcomes:
- Behavior visibility: It identifies functional response patterns such as Planning, Memory, Feedback, and Reflection instead of treating all outputs as the same kind of text.
- Longitudinal insight: It tracks how those patterns shift across conversations and over time, making behavioral change easier to study.
- Reproducible analysis: It turns subjective impressions of personalization into outputs that can be reviewed, rerun, and compared more systematically.
Analysis
Automated Behavioral Mapping
NeuroTrace applies modular analysis steps to transform raw interaction data into structured behavioral views:
- Behavioral tagging: Assigns assistant responses to functional zones such as Planning, Memory, Feedback, and Reflection.
- Transition analysis: Builds transition patterns between zones to show how behaviors connect across interactions.
- Structural depth: Measures how response structure changes as the assistant accumulates more context over time.
Reliability
Reproducible Research Pipeline
The framework is built to make findings easier to verify:
- Deterministic processing: Raw interaction logs are transformed into stable CSV and JSON outputs through a repeatable runtime pipeline.
- Modular architecture: Tagging, metrics, response-depth analysis, zone transitions, and semantic memory analysis can run independently or together.
- Audit-ready outputs: Visualizations and reported findings are backed by generated artifacts rather than one-off manual interpretation.
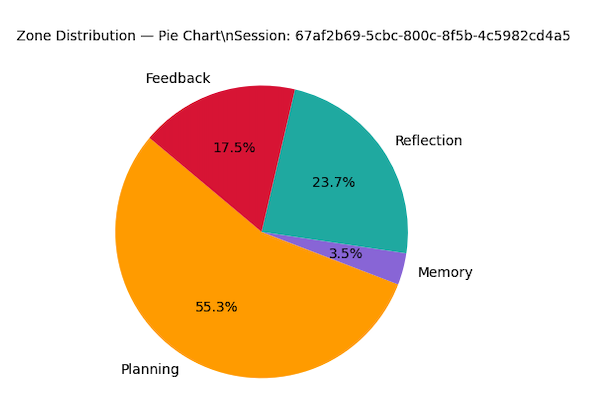
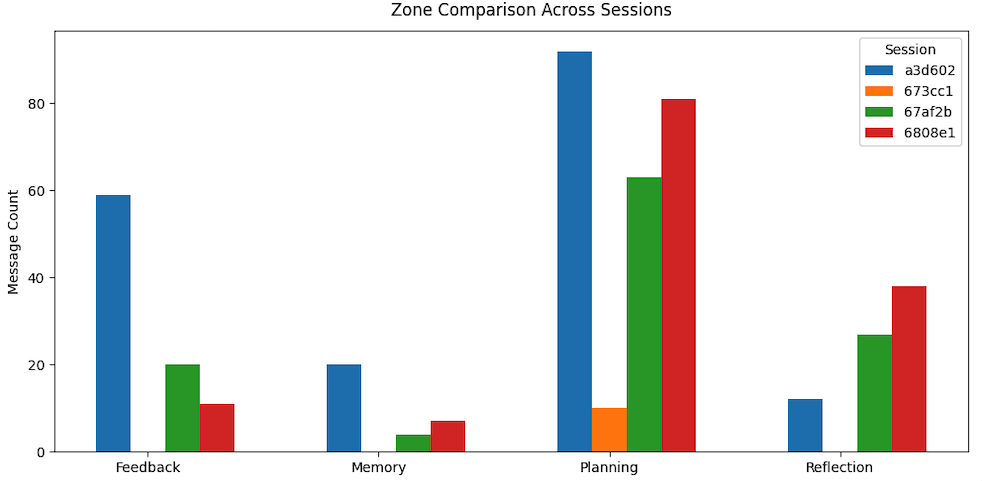
Impact and findings
NeuroTrace became the technical framework behind the research paper Personalization in Memory-Enabled AI Systems: A Graph-Based Analysis of Evolving User Interaction Patterns. The work showed that assistant behavior can be modeled as evolving functional patterns rather than treated as isolated outputs, and it identified a recurring Feedback -> Planning corrective loop in the analyzed interactions.
In simple terms: NeuroTrace turns AI personalization from a vague impression into something that can be inspected, measured, and discussed with evidence.